▶SQL (Structured Query Language)
→ 관계형 데이터베이스 관리 시스템(RDBMS)의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어

※ 데이터 생명주기 : 데이터가 생성되고 소멸까지 모든 단계
1. DDL (Data Definition Language, 데이터 정의어)
→ 구조를 생성, 수정, 삭제
1) CREATE
→ 데이터 베이스 오브젝트 생성
2) ALTER
→ 데이터 오브젝트 변경
3) DROP
→ 데이터 오브젝트를 삭제
4) TRUNCATE
→ 데이터 오브젝트 내용 삭제 (구조를 날리고 다시 생성)
※ 데이터 오브젝트 = 테이블
2. DML (Data Manopulation Language, 데이터 조작어)
→ 테이블 내용을 삽입, 수정, 삭제, 조회
1) INSERT
→ 테이블 신규 내용 삽입
2) SELECT
→ 테이블 내용 조회
3) UPDATE
→ 테이블의 내용을 변경
4) DELETE
→ 테이블의 내용 삭제
3. DCL (Data Control Language, 데이터 제어어)
→ 사용자에게 권한 부여 및 회수
1) GRANT
→ 데이터 베이스 사용자에게 권한을 부여
2) REVOKE
→ 데이터 베이스 사용자에게 권한을 회수
4. TCL (Transaction Control Language, 트랜잭션 조작어)
→ DML에 의해 조작된 결과를 트랜잭션 별로 제어
1) COMMIT
→ 트랜잭션 확정
2) ROLLBACK
→ 트랜잭션 취소
3) CHECKPOINT
→ 복귀지점 설정
※ 트렌잭션은 다음에 자세하게 다룸
▶ HeidiSQL을 이용한 SQL 명령어 실행
예시)
-- 데이터베이스 생성
/* 데이터베이스 생성 */
CREATE DATABASE ksmart45db DEFAULT CHARACTER SET UTF8;
/* 데이터베이스 조회 */
SHOW DATABASE;
-- 사용자 계정 추가
CREATE USER 'ksmart45id'@'%' IDENTIFIED BY 'ksmart45pw';
-- 해당 쿼리만 실행시키고 싶으면 블럭 처리후 ctrl + F9
/* 1. 데이터베이스 ksmartdb 생성 */
CREATE DATABASE ksmartdb DEFAULT CHARACTER SET UTF8;
/* 2. 사용자 계정 추가 */
CREATE user 'ksmart'@'%' IDENTIFIED BY 'ksmartpw';
/* 3. 데이터베이스 ksmartdb 삭제 */
DROP DATABASE ksmartdb;
/* 4. 사용자 계정 삭제 */
DROP user 'ksmart'@'%';
/* 5. 사용자 계정 권한 부여 */
GRANT ALL PRIVILEGES ON ksmart45db.* TO 'ksmart45id'@'%';
/* 6. 사용자 계정 권한 회수 */
REVOKE ALL PRIVILEGES ON ksmart45db.* FROM 'ksmart45id'@'%';
/* 변경된 내용을 메모리에 반영 */
FLUSH PRIVILEGES;※ 작성시 오타로 오류가 나거나 새로고침을 하지 않아서 권한 혹은 아이디를 제거하고 확인이 제대로 되지 않아서 오류가 난 부분이 있으므로 주의를 해주어야 한다.
※ 주석은 --와 /* */로 2가지 있으며 --는 해당 줄만 주석처리, /**/는 /**/ 사이에 있으면 전부 주석처리가 된다.
▶ DDL 명령어 구조
1. CREATE문
CREATE (DATABASE, USER 등 만들 것 선택) 선택한 것 이름;테이블 생성 예시)
CREATE TABLE 테이블 이름 (
u_id VARCHARACTER(100) NOT NULL PRIMARY KEY COMMENT '사용자 아이디',
u_pw VARCHARACTER(100) NOT NULL COMMENT '사용자 비밀번호',
u_name VARCHARACTER(100) NOT NULL COMMENT '사용자 이름',
u_birth DATE COMMENT '사용자 생년월일',
u_add VARCHARACTER(100) NOT NULL COMMENT '사용자 주소',
u_mobile1 VARCHARACTER(100) COMMENT '사용자 연락처1',
u_mobile2 VARCHARACTER(100) COMMENT '사용자 연락처2',
u_date DATE COMMENT '등록일자'
);- u_id와 같은 부분은 칼럼 이름을 입력하는 부분이다.
- 코멘트는 테이블의 컬림 이름보다 좀 더 보기 쉽게 하기 위해 입력하는 것
- PRIMARY KEY : 한 테이블에 프라이머리 키가 설정된 칼럼에 같은 값이 들어가면 안 됨
- 대소문자 구분을 하지 않기 때문에 스네이크 케이스로 작성 (ex. u_id .... )
※ 테이블 복사
CREATE TABLE 테이블명 (
SELECT
해당 테이블에 복사할 행
FROM
복사할 테이블 명
);→ 키들은 복사되지 않음
※ AUTO_INCREMENT
CREATE TABLE 'test'(
'num' int(10) NOT NULL AUTO_INCREMENT PRIMARY KEY,
'name' varchar(10) NOR NULL
);→ PRIMARY KEY를 겹치치 않게 1씩 증가하며 사용가능
2. ALTER문
/* 컬럼명 변경 */
ALTER TABLE tb_user CHANGE COLUMN u_reg_date u_date DATE;
ALTER TABLE 테이블명 CHANGE 기존 컬럼명 변경할 컬럼명 컬럼타입;
/* 컬럼 순서변경 */
ALTER TABLE tb_user MODIFY u_mobile2 VARCHAR(100) AFTER u_mobile1;
ALTER TABLE 테이블명 MODIFY 순서 변경할 컬럼명 컬럼타입 AFTER 앞에 오는 컬럼명;
/* 컬럼 디폴트값 변경 */
ALTER TABLE tb_user ALTER COLUMN u_add SET DEFAULT NULL;
ALTER TABLE 테이블명 ALTER COLUMN 변경할 컬럼명 SET DEFAULT 디폴트 값;
/* 컬럼 타입변경 */
ALTER TABLE tb_user MODIFY u_add VARCHAR(150);
ALTER TABLE 테이블명 MODIFY 컬럼명 변경할 컬럼타입;
/* 컬럼 추가 */
ALTER TABLE tb_user ADD COLUMN u_email VARCHAR(100) AFTER u_add;
ALTER TABLE 테이블명 ADD COLUMN 추가할 컬럼명 컬럼타입 DEFAULT 디폴트 값 컬럼위치;
/* 컬럼 삭제 */
ALTER TABLE tb_user DROP COLUMN u_email;
ALTER TABLE 테이블명 DROP COLUMN 컬럼명;
3. DROP문
DROP (DATABASE, USER 등 종류) 선택한 것 이름;4. TRUNCATE문
TRUNCATE TABLE 테이블명;
▶ DML 명령어 구조
→ 행을 중심으로 작업이 이루어짐
1. INSERT문
INSERT INTO 테이블 이름 (
/* 열의 이름 (컬럽 값) */
) VALUES(
/* 컬럼마다 입력할 값을 순서대로 기입 */
);
※ DATE 함수
1, NOW() : 현재 날짜와 시간을 보여줍니다.
2, CURDATE() : 현재 날짜를 보여줍니다.
3, CURTIME() : 현재 시간을 보여줍니다
※ 이와 같이 여러 행 한 번에 삽입 가능
INSERT INTO tb_user(u_id, u_pw, u_name, u_birth, u_add, u_mobile1, u_mobile2, u_date)
VALUES
('id001', 'pw001', '홍01', '2020-03-10', '덕진동', '010', '00010001', '2020-03-10'),
('id002', 'pw002', '홍02', '2020-03-10', '호성동', '010', '00020002', '2020-03-10'),
('id003', 'pw003', '홍03', '2020-03-10', '금암동', '010', '00030003', '2020-03-10'),
('id004', 'pw004', '홍04', '2020-03-10', '조촌동', '010', '00040004', '2020-03-10'),
('id005', 'pw005', '홍05', '2020-03-10', '서서학동', '010', '00050005', '2020-03-10'),
('id006', 'pw006', '홍06', '2020-03-10', '금암동', '010', '00060006', '2020-03-10'),
('id007', 'pw007', '홍07', '2020-03-10', '송천동', '010', '00070007', '2020-03-10'),
('id008', 'pw008', '홍08', '2020-03-10', '서신동', '010', '00080008', '2020-03-10'),
('id009', 'pw009', '홍09', '2020-03-10', '효자동', '010', '00090009', '2020-03-10'),
('id010', 'pw010', '홍10', '2020-03-10', '삼천동', '010', '00100010', '2020-03-10');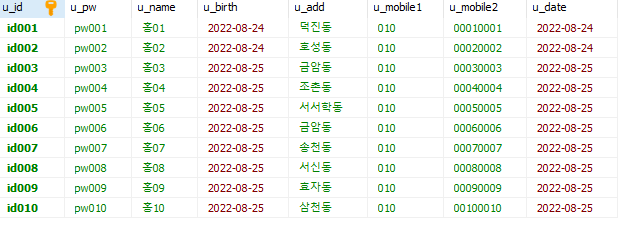
※ 중복 키 발생 시 변경법
INSERT INTO tb_user (
u_id, u_pw, u_name, u_birth, u_add, u_mobile1, u_mobile2, u_date
) VALUES (
'id001', 'pw001', '홍 01', CURDATE(), '덕진동', '010', '00010001', CURDATE()
) ON DUPLICATE KEY UPDATE
u_birth='2002-08-23',
u_add='금암동';
--또는
INSERT IGNORE INTO tb_user (
u_id, u_pw, u_name, u_birth, u_add, u_mobile1, u_mobile2, u_date
)
VALUES(
'id010','pw010','홍10','2020-10-10','덕진동','010','00010001','2020-03-10'
);→ INSERT문에서 중복 발생하고 UPDATE를 사용할 수 없을 시 'ON DUPLICATE KEY UPDATE' 또는 'IGNORE' 사용
2. SELECT문
SELECT * FROM tb_user;→ SELECT를 이용해서 *(전체)를 FROM 뒤에 있는 테이블에 서 조회한다
☞ tb_user 테이블의 전체를 조회한다.
※ 예시
/* from -> where -> select 순서 */
SELECT
u_id,
u_pw
FROM
tb_user
WHERE
u_id='id001'
-- tb_user에 있는 u_id가 id001인 u_id와 u_pw를 조회하라→ WHERE는 조건을 입력하여 해당하는 부분만 조회
결과

※ 별칭 주기
SELECT
u_id AS userId,
u_pw AS userPw
FROM
tb_user;
/* 또는 AS없이 빈 칸 하나 뒤에 입력*/
SELECT
u_id userId,
u_pw userPw
FROM
tb_user;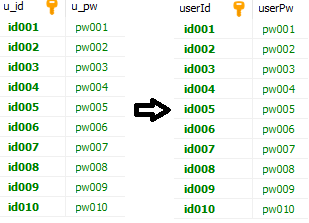
※ 오름차순 혹은 내림 차순으로 정렬 조회
SELECT
조회할 행 or 행들
FROM
테이블 명
ORDER BY
기준 행 DESC;
/* ASC 는 오름차순 */* 내가 원하는 대로 정렬
SELECT
DISTINCT u_add AS '주소'
FROM
tb_user
ORDER BY FIELD(u_add,'금암동','덕진동',
'송천동','호성동','서신동',
'조촌동','서서학동','효자동',
'삼천동');→ FIELD를 사용한다.

※ 행의 개수 제한
SELECT
조회할 행 또는 행들
FROM
테이블 명
LIMIT 숫자;→ LIMIT을 이용하여 뒤에 나오는 숫자만큼만 조회
※ LIMIT 2, 3과 같이 2개 입력시 3번(0부터 시작하므로 3번째 인덱스가 2이다.) 인덱스부터 3개 조회
※ 중복 제거
SELECT DISTINCT
행입력
FROM
테이블 명→ 행 기준으로 중복 제거 (입력된 모든 행을 기준으로 한다.)
※ 그룹함수
SELECT
행 선택
,COUNT(u_id) AS '고객분포수'
FROM
테이블 명
GROUP BY 그룹으로 묶을 기준;→ 그룹함수사용시 SELECT보다 먼저 실행 됨
* COUNT 함수는 그룹으로 묶은 기준 마다 갯수를 조회
* HAVING
→ 그룹 출력 조건식
SELECT
행 선택,
COUNT(개수를 표시할 기준)
FROM
테이블 명
GROUP BY
그룹 기준
HAVING
그룹에 관련된 조건;
3. UPDATE문
UPDATE 테이블 명 SET 변경할 내용 WHERE 조건문;
4. DELETE문
DELETE FROM 테이블 명 WHERE 조건문;* 모든 데이터 삭제
DELETE FROM 테이블 명;
▶ DCL 명령어 구조
1. GRANT문
GRANT ALL PRIVILEGES ON 데이터베이스 명.* TO '사용자명'@'주소';
2. REVOKE문
REVOKE ALL PRIVILEGES ON 데이터 베이스 명.* FROM '사용자명'@'주소';
▶ HeidiSQL을 이용하여 코드 없이 실행

→ 코드가 아닌 HeibiSQL로 하는 방법

→ 위와 같이 프리가 머리와 같은 키를 설정할 수 있다.
'코딩 공부 > web & Java' 카테고리의 다른 글
| 관계형 데이터 모델과 키, 제약 조건 (0) | 2022.08.25 |
|---|---|
| 데이터 모델링 (0) | 2022.08.25 |
| MySQL 제거 (0) | 2022.08.24 |
| 데이터 베이스관련 (0) | 2022.08.24 |
| 이클립스, 톰캣 설치 및 부가 설명, 자바의 기본적인 구조 (0) | 2022.08.23 |



